
Was bedeutet die “403 Forbidden” Fehlermeldung und was kannst Du tun um diesen Fehler zu beheben? Ursachen, Lösungen und Tipps für den Fehlercode.
Wir alle kennen den bekannten 404 Fehler, möglich sind aber auch Fehler 403. Diese entstehen, wenn ein Client auf eine Ressource zugreift, für die er keine Berechtigung hat. Wir zeigen Dir hier, wie der Fehlercode 403 entsteht, welche Konsequenzen er haben kann und was Du dagegen tun kannst.
Und hier die ausführliche Erklärung zu Fehlercode 403 Forbidden:
Wenn ein Client, zum Beispiel ein Browser, per http eine URL von einem Server abrufen will, wird diese Anfrage zuerst vom Server geprüft. Ist die Seite vorhanden und kann ausgegeben werden, sendet der Server den Status Code 200 OK. Der Browser kann die Webseite dann laden und dem Nutzer anzeigen. Diese “Verhandlung” zwischen Client und Server bleibt für Nutzer in der Regel unbemerkt. Es sei denn, es treten Fehler auf.
Mögliche Fehler sind sogenannte 4xx-Fehler. Sie gehören zur Klasse der Client-Fehler. Der Error 403 gehört wie der Fehlercode 404 auch dazu. Greift nun ein Browser auf einen Server per http zu, kann der Server den Zugriff verweigern. In diesem Fall gibt der Server den http Code 403 aus und der Browser kann nicht auf die gewünschte Ressource zugreifen.

Abbildung 1: 403 Forbidden-Hinweis des Servers beim versuchten Zugriff auf eine Admin-Seite eines WordPress-Blogs
Auch wenn der 403 Status Code zunächst einen Client-Fehler suggeriert, liegt es letztlich an den Server-Einstellungen oder an den Einstellungen des jeweiligen CMS, ob ein Client Zugriff auf bestimmte Verzeichnisse bzw. URLs hat oder nicht.
Aus Suchmaschinensicht ist ein 403 Error ebenfalls ein Manko, denn der Googlebot kann die Inhalte der betreffenden URLs nicht crawlen und wie ein Browser rendern. Somit riskierst Du, dass die entsprechenden Seiten aus dem Google-Index entfernt werden.
Im Jahr 2014 hatte Matt Cutts noch eine Art Kulanzzeit von 24 Stunden eingeräumt, wenn der Googlebot eine Seite mit http Status 403 gefunden hatte. Diese Zeit gab das System laut Cutts der URL, um im Crawling-System zu bleiben.
In einer SEO-Fragerunde auf Reddit hat Googles John Mueller sich ebenfalls zum Thema 4xx-Fehler geäußert. Dort wurden die Hinweise konkreter:

Abbildung 2: Statement von John Mueller zu 4xx-Fehlern (Quelle)
Somit ist klar: Sollte eine URL auf eine Client-Anfrage, also auch eine Googlebot-Anfrage keinen Content ausliefern, wird sie aus dem Index entfernt.
Neben dieser sinnvollen Einschränkung können Nutzer ausgeschlossen werden, wenn Verzeichnisse unbeabsichtigt gesperrt werden. Durch diesen Ausschluss zeigt der Browser dem User auch eine 403 Forbidden-Meldung an. In folgenden Fällen kann das geschehen:
Darüber hinaus können auch für Bots 403 Forbidden Error entstehen, wenn Sie versuchen, Deine Website zu crawlen. Verursacht werden diese Fehler dann, wenn der Googlebot zum Beispiel wichtige Verzeichnisse aufgrund der Vorgaben in der robots.txt nicht durchsuchen darf, die aber für die Funktionalität Deiner Website wichtig sind. 403 Fehler sind ebenfalls möglich, wenn Du über die robots.txt zentrale Verzeichnisse mit Content vom Crawling ausschließt.
Darüber hinaus kannst Du unter Quality Assurance die Status Codes Deiner Website abrufen. Beachte dabei, wann Dein Projekt letztmalig gecrawlt wurde.
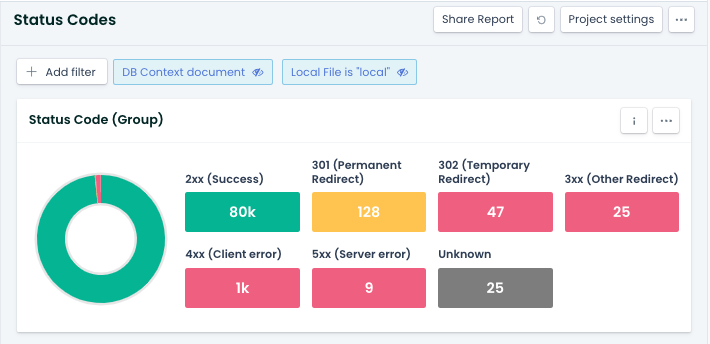
Abbildung 3: Status Codes einer Website mit Ryte prüfen
Auch die Google Search Console (GSC) zeigt Dir, ob 403-Fehler vorliegen. Die entsprechenden Meldungen findest Du im Bereich „Abdeckung“:
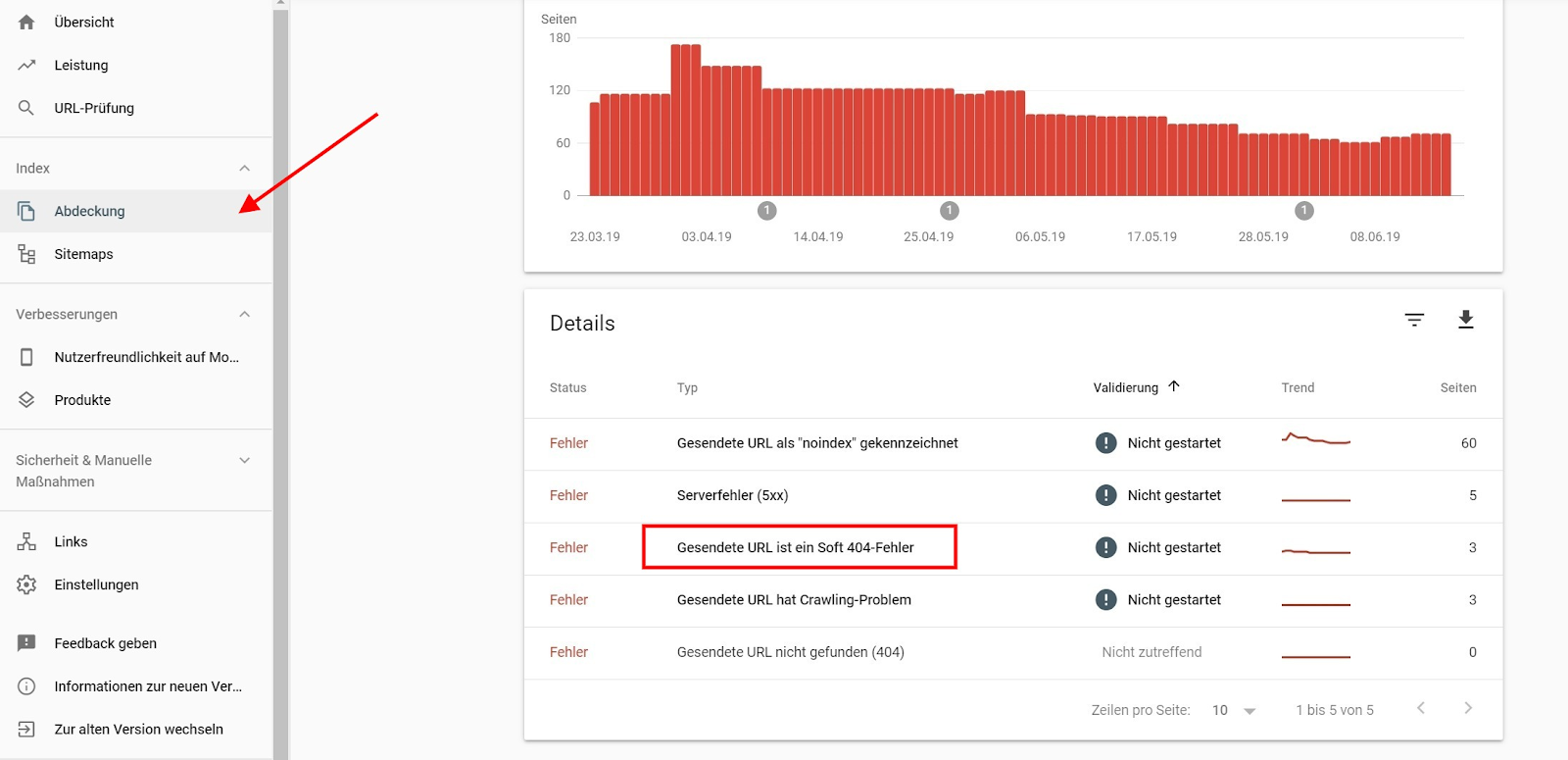
Abbildung 4: Crawling-Fehler mit der GSC ermitteln
Für diese Prüfung Deiner robots.txt kann Dich Ryte unterstützen. Der Bericht „Robots.txt Monitoring“ unter SEO zeigt dir, welche Bereiche aktuell nicht gecrawlt werden dürfen. (Disallowed)
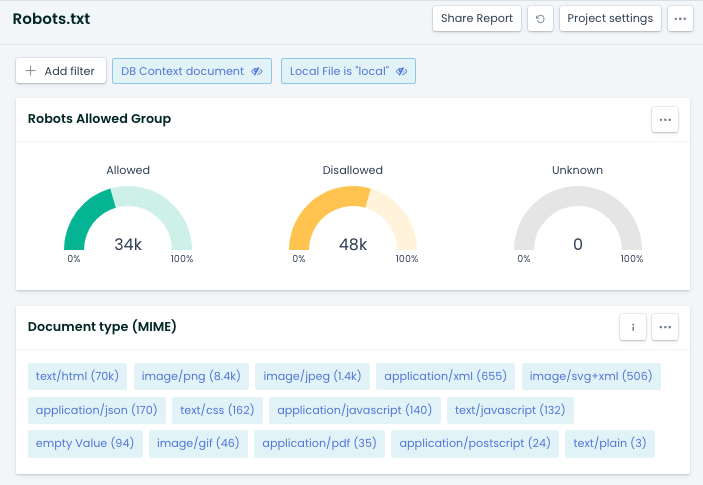
Abbildung 5: robots.txt mit Ryte prüfen
Die Google Search Console eignet sich ebenfalls, um die robots.txt zu prüfen. Den Report findest Du im Segment “Crawling” noch in der alten Version der GSC. Bis dato wurde der robots.txt-Tester noch nicht in die neue Benutzeroberfläche integriert. (Stand: Dez 2019)
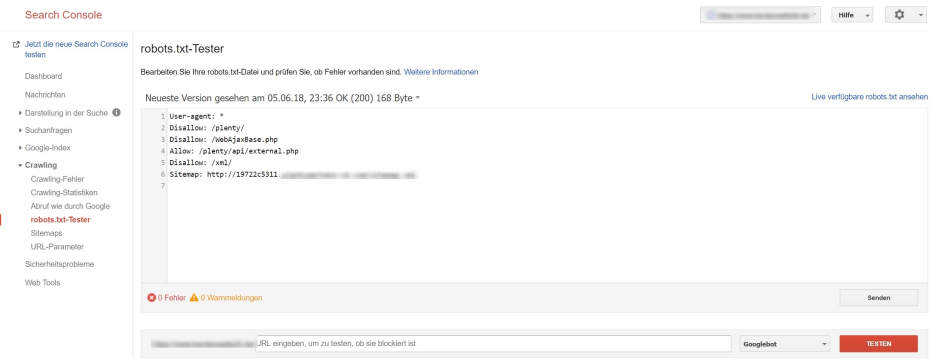
Abbildung 6: robots.txt mit der GSC testen
Mit dem Tool “Abruf wie durch Google” hast Du außerdem die Möglichkeit zu prüfen, ob der Googlebot am Crawling wichtiger Bereiche durch Einschränkungen in der robots.txt gehindert wird.
403 Forbidden-Status Codes sind zwar zunächst Client-Fehler, doch entstehen diese Fehler auch durch eine fehlerhafte Konfiguration des Servers oder der robots.txt-Datei. Um zu vermeiden, dass Google mittelfristig URLs aus dem Index ausschließt, weil sie keinen Content liefern können und um eine mangelhafte User Experience zu vermeiden, solltest Du bei 403 Error-Seiten schnell handeln.
Optimiere Deine Website mit Ryte!
Im 360° Ryte Trial kannst Du alle Features der Ryte WUX Plattform - inklusive Status Codes-Report - 10 Tage kostenlos testen.
Veröffentlicht am 04.08.2021 von Marcus Tandler.

Marcus liebt SEO. Er ist stolzes Mitglied im Stamm der Achuar, und sein indianischer Name "Ni Nawenak Ukutin" ("Weißer Krieger, der sich selber in den Fuß schießt") offenbart, wieso er im Dschungel keine Waffe mehr tragen darf. Marcus kann sich tagelang ausschließlich von Brezn, Kaiserschmarrn und Streuselkuchen ernähren, und weiß wer an der Uhr gedreht hat!