Crawler
Ein Crawler ist ein Computerprogramm, das automatisiert Dokumente im Web durchsucht. Primär wird ein Crawler für sich wiederholende Aktionen programmiert, damit das Durchsuchen gänzlich automatisiert abläuft. Suchmaschinen setzen Crawler verstärkt ein, um das WWW zu durchsuchen und einen Index aufzubauen. Andere Crawler wiederum können unterschiedliche Arten von Informationen durchsuchen wie RSS-Feedsoder E-Mail Adressen. Der Begriff Crawler stammt von der ersten Suchmaschine für das Internet, dem Webcrawler. Heute gebräuchliche Bezeichnungen sind auch Webspider, Webcrawler, Spider, Searchbot, Suchmaschinencrawler, Suchmaschinenrobot oder einfach nur Bot. Der bekanntest Webcrawler ist der Googlebot.
Wie funktioniert ein Crawler?
Im Prinzip arbeitet ein Crawler ähnlich wie ein Bibliothekar. Er sucht nach Informationen im Web, die er bestimmten Kategorien zuordnet und anschließend indiziert bzw. katalogisiert, damit die gecrawlten Informationen abruf- und auswertbar sind. Während der Bibliothekar selbst bestimmt arbeitet und sich und seinem Team Aufgaben vorgibt, unterscheidet sich der Crawler davon. Denn er handelt nicht eigenständig.
Die Arbeitsschritte dieser Computerprogramme müssen vor Ablauf eines sogenannten Crawls festgelegt werden. Jeder Auftrag ist somit im Voraus definiert. Der Crawler selbst „arbeitet“ diese Vorgaben automatisch ab. Klassischerweise wird mit den Ergebnissen des Crawlers ein Index angelegt, auf den über eine Ausgabesoftware zugegriffen wird.
Welche Informationen ein Crawler aus dem Web bezieht, hängt von der jeweiligen Aufgabenstellung ab. Grafik welche die Linkbeziehungen visualisiert, die von einem Crawler aufgedeckt wurden:
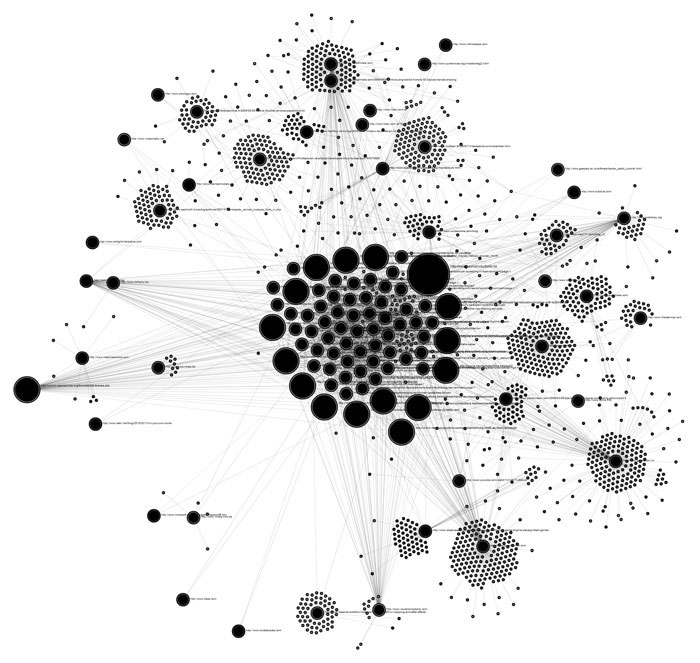
Grafische Darstellung eines Crawlers (Quelle: neuroproductions.be)

Einsatzgebiete
Das klassische Ziel eines Crawlers ist das Erstellen eines Index. Somit sind Webcrawler die Basis für die Arbeit von Suchmaschinen. Diese durchforsten zunächst das Web nach Inhalten, um die Ergebnisse anschließend für User verfügbar zu machen. Focused Crawler konzentrieren sich z.B. bei der Indizierung auf besonders aktuelle, themenrelevante Webseiten.
Doch Webcrawler werden auch für weitere Disziplinen eingesetzt:
- Preisvergleichsportale suchen nach Informationen zu bestimmten Produkten im Web, damit Preise oder Daten genauer verglichen werden können.
- Im Bereich des Data Mining kann ein Crawler z.B. öffentlich erreichbare E-Mail- oder Postadressen von Unternehmen sammeln.
- Tools zur Webanalyse sammeln mit Hilfe von Crawlern bzw. Spidern Daten zur Seitenaufrufen oder zu eingehenden Links oder ausgehenden Links.
- Crawler dienen dazu, Informationshubs mit Daten zu versorgen, z.B. Nachrichtenseiten.
Crawler vs. Scraper
Ein Crawler ist im Gegensatz zum Scraper lediglich ein Datensammler und bereitet diese Daten auf. Beim Scraping handelt es sich jedoch um eine Black Hat Technik, die darauf abzielt, Daten in Form von Content von anderen Seiten zu kopieren, um diese in gleicher oder leicht abgewandelter Form auf einer eigenen Website zu platzieren. Während ein Crawler demnach eher mit Meta-Informationen umgeht, die für den User auf den ersten Blick nicht sichtbar sind, greift der Scraper handfeste Inhalte ab.
Einen Crawler sperren
Wer nicht möchte, dass bestimmte Crawler seine Website durchsuchen, kann deren User Agents über die robots.txt ausschließen. Doch damit kann nicht verhindert werden, dass Inhalte durch Suchmaschinen indiziert werden. Hierfür eignet sich dann eher der noindex-Metatag oder der Canonical Tag.
Bedeutung für die Suchmaschinenoptimierung
Webcrawler wie der Googlebot schaffen durch das Crawling und Indexing die Voraussetzung dafür, dass Webseiten überhaupt in den SERP ranken können. Sie folgen dabei permanent Links im WWW und auf Webseiten. Pro Seite hat jeder Crawler nur einen begrenzten Zeitraum zur Verfügung, auch Crawl Budget. Durch die Optimierung der Webseitenstruktur sowie der Navigation und der Dateigröße können Webseitenbetreiber das Crawl Budget des Googlebots zum Beispiel besser ausnutzen. Zugleich erhöht sich das Budget durch eine Vielzahl eingehender Links und eine stark frequentierte Seite. Wichtige Instrumente, um Crawler wie den Googlebot zu steuern, sind letztlich jedoch die robots.txt-Datei sowie die in der Google Search Console hinterlegte XML-Sitemap. In der Google Search Console kann darüber hinaus geprüft werden, ob alle relevanten Bereiche einer Webseite vom Googlebot erreicht und indexiert werden können.
Weblinks