Inverse Document Frequency
Unter Inverse Document Frequency (Abk.: IDF) versteht man in der Informationswissenschaft und Informationsstatistik eine Methode, um die Häufigkeit eines Wortes innerhalb eines Datensatzes an Texten zu ermitteln. In Kombination mit der Within Document Frequency hilft die Inverse Document Frequency dabei, möglichst einzigartigen Content zu erstellen und löst so u.a. den lange für die Textqualität verwendeten Qualitätsfaktor Keyworddichte ab.
Hintergrund
Mitte der 1960er-Jahre hat der US-Forscher C.W. Cleverdon in seinem Werk „The Cranfield tests on index language devices“ bedeutend an der Erforschung der Termgewichtung gearbeitet. Ein Ziel dieser Arbeiten war es u.a., vorhandene Dokumente besser zu indizieren.
In der Folge haben sich Mathematiker und Statistiker immer wieder darum bemüht, eine passende Formel zu finden, um die Bedeutung eines Wortes innerhalb eines Datensatzes an Dokumenten zu ermitteln. Wurde zunächst noch mit Themen und der Vorauswahl einiger Begriffe gearbeitet, setzte sich schließlich sukzessive die Ansicht durch, dass alle Wörter eines Dokumentes für die Analyse verwendet werden müssen, um die Termgewichtung innerhalb eines Gesamtkorpus zu bestimmen. Die IDF-Formel war schließlich das Ergebnis dieser Forschungen.
Die Inverse Document Frequency wird mit Hilfe einer Logarithmus-Rechnung bestimmt. Dabei ist sie der Quotient aus allen vorhandenen Texten bzw. Dokumenten eines gesamten Datensatzes und der Zahl der Texte, die das definierte Keyword enthalten.
Die Formel zur Berechnung sieht also folgendermaßen aus:
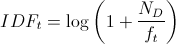
wobei 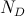 die Anzahl der Dokumente bezeichnet und
die Anzahl der Dokumente bezeichnet und
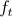 die Anzahl der Dokumente, die den Term
die Anzahl der Dokumente, die den Term 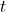 enthalten.
Wenn die Dokumentenhäufigkeit wächst, wird der Bruch kleiner.
enthalten.
Wenn die Dokumentenhäufigkeit wächst, wird der Bruch kleiner.
Nutzen
Die inverse Dokumentenhäufigkeit allein kann dabei helfen, speziell die Besonderheit eines Schlüsselbegriffs anhand eines vorhandenen Dokumentenkorpus zu bestimmen. Allerdings sagt die Termgewichtung innerhalb eines Datensatzes noch nichts über die Einzigartigkeit eines Textes aus.
Deshalb wird für die Contentoptimierung die Formel WDF*IDF verwendet, um damit das Resultat auf ein vorliegendes Dokument beziehen zu können. Wichtig bei der Analyse ist dabei sicherlich auch, dass eine solche Analyse bei Webseiten nicht nur den reinen Textkorpus mitberücksichtigt, sondern alle im Quellcode hinterlegten Texte, somit auch Seitentitel und Alt-Tags.
Weblinks