WDF
Unter WDF (englisch: Within Document Frequency) versteht man die Gewichtung eines Wortes in einem Dokument. Der Begriff stammt aus der Informationsstatistik, die Worthäufigkeiten in Dokumenten und Wortgewichtungen ermittelt und daraus ein Ranking der Dokumente nach Relevanz ableitet. Im Zusammenspiel mit der Inverse Document Frequency (IDF) ergibt die WDF eine Formel, nach welcher die Einzigartigkeit eines Textes in Bezug auf ein Keyword bzw. eine Keywordkombination ermittelt werden kann.
Hintergrund
Die Berechnung dieser Häufigkeit wurde von Donna Harman in Ihrem Beitrag „Ranking Algorithms“ innerhalb des Sammelbandes „Information Retrieval: Data Structures & Algorithms“ aus dem Jahr 1992 entwickelt, um bestimmten Ausdrücken eine Gewichtung in einem Dokument zu geben.[1] Die Berechnung der WDF dient der Aufbereitung von Datenbeständen in der Informationswissenschaft. Häufig wird WDF zusammen mit IDF und dem Gewichtungswert P erwähnt. Miteinander multipliziert stellen diese Größen eine Gewichtungsformel dar, welche u.a. die Einzigartigkeit von Textmaterial in Bezug auf bestimmte Schlüsselbegriffe bestimmen kann. In der Regel gilt: Je höher die WDF, desto häufiger kommt ein Begriff in einem Dokument vor. Mit Hilfe der WDF können u.a. Bibliotheken ihre Bestände leichter durchsuchen. Dabei erhalten die Nutzer Suchergebnisse, die sich den bestmöglichen Treffer zu einem bestimmten Suchbegriff aufführen und sich dabei nicht allein nur nach der Begriffsdichte orientieren, sondern den Kontext mit einbeziehen können.
Berechnung der WDF
Die Formel für die Within Document Frequency - WDF lautet wie folgt:
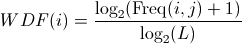
i=:Wort
j=:Dokument
L=:Gesamtzahl der Wörter in Dokument j
Freq(i,j)=:Häufigkeit des Wortes i im Dokument j
Erklärung zu "+1":
falls Freq(i,j) = 0 ist, erreicht man mit dem "+1" dass im Zähler log2(1) = 0 steht.
Beispiel
Angenommen ein Dokument j enthält 12.000 Wörter, dann ist L=12000. Das Wort i kommt in diesem Dokument j 23 mal vor, also ist Freq(i,j)=23. Beim Einsatz der Werte ergibt sich folgende Berechnung:
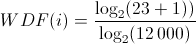
Das Ergebnis ist der Gewichtungswert WDF(i)= 0,3 (gerundet). Die relative Häufigkeit des Wortes i ist dagegen 0,001.
WDF vs. Keyword-Dichte
Mit der Within Document Frequency wird die Termgewichtung innerhalb eines Dokuments angeben. Anders als bei der Bestimmung der Keyworddichte, wird die WDF für sinntragende Wörter errechnet und nicht durch einen einfachen Dreisatz bestimmt. Mit Hilfe zweier Logarithmen wird zusätzlich verhindert, dass der WDF-Wert durch das massive Hinzufügen von Schlüsselbegriffen in einen Textkorpus künstlich erhöht werden kann. Grundsätzlich kann folglich durch die Berechnung der WDF ermittelt werden, welcher Term bzw. welche Begriffe einen Text am besten beschreiben.[2]
Bedeutung für SEO
Mit der Wiederentdeckung der zunächst vor allem für wissenschaftliche Recherchen verwendeten Formel WDF*IDF zur Content-Optimierung im Web, wurde die bis dahin weit verbreitete, vergleichsweise simple KPI der Keyworddichte durch die komplexere WDF abgelöst. Bei der WDF-Analyse ging es plötzlich nicht mehr nur darum, was gesagt wurde, sondern auch darum, wie. Bei der WDF wird das verwendete Keyword nicht nur auf seine Frequenz in einem HTML-Dokument hin untersucht, sondern auch dessen kontextuelles und semantisches Umfeld berücksichtigt. Darum gilt sie als die aussagekräftigere und zuverlässigere KPI im Vergleich zur reinen Keyworddichte. Im Rahmen der Evolution von Crawlern und Algorithmen ist eine KPI oder eine Formel, die den Gesamtkontext betrachtet, einer KPI, die nur einen einzelnen Faktor berücksichtigt vorzuziehen. So ist die WDF mittlerweile zum Standard bei der Suchmaschinenoptimierung von Text-Content avanciert. Doch auch WDF stößt an seine Grenzen.
Grenzen der WDF
Besonders im E-Commerce stoßen WDF und IDF an ihre Grenzen. Shop-Seiten mit wenig Text-Content könnten durch die WDF*IDF-Brille überoptimiert oder als Duplicate Content erscheinen.[3] Die WDF eignet sich demnach vor allem für längere Text-Dokumente. Doch auch dort sollte die WDF nicht dogmatisch wie eine Schablone auf jedes Content Piece gelegt werden. Denn besonders im Zeitalter der User Centricity sollte Content zuvorderst für den User und erst in zweiter Instanz für den Googlebot geschrieben werden. In Zeiten, in denen Semantik und natürliche Sprache auch für das Ranking zunehmend wichtiger werden, sollte Content Creator es vermeiden, ihre Inhalte in ein starres Framework aus KPIs zu pressen.
Einzelnachweise
- ↑ Information Retrieval: Data Structures & Algorithms Semantic Scholar. Abgerufen am 19.12.2021
- ↑ Die ganze Wahrheit über die WDF*IDF-Analyse Ryte Magazine. Abgerufen am 19.12.2021
- ↑ WDF*IDF Erläuterung wdfidf.net. Abgerufen am 19.12.2021