Vom Dschungel zum Schrebergarten: Durch weniger URLs zu mehr Such-Traffic
Viele Webseiten gleichen einem URL-Dschungel. Das kostet häufig Rankings und Traffic. Man kann es verhindern, wenn man den URL-Umfang seiner Webseite monitort, unnütze URLs identifiziert und entfernt.
Die höchsten Rankings, der beste Content, die stärksten Links – bei SEO geht es meist darum, durch mehr irgendwas mehr Traffic zu generieren. Viele Webseiten gleichen daher heute eher einem URL-Dschungel als einem wohlgepflegten Schrebergarten. Auch wenn Tante Google kein Problem mit ein bisschen Chaos hat, mag sie doch die Webseiten, die auf sich achten, am liebsten.
Wie generiere ich mehr Traffic mit weniger URLs? Dieser Frage wollen wir uns heute widmen.
Die Vision – Welche Vorteile hat eine schlanke Webseite?
Im ersten Moment klingt "mehr Traffic durch weniger URLs" kontraintuitiv. Wenn meine Webseite weniger URLs hat, dann kann sie auf weniger Themen (manche sagen noch „Keywords") ranken. Würde jede URL einer Webseite über den besten Content zu einem anderen Thema verfügen, dann wäre das richtig. Nur ist dem leider in der Praxis nicht so. Genauer gesagt: nie.
Dabei spricht vieles für weniger URLs. So hat die Gesamtqualität einer Webseite Auswirkungen auf ihre Rankingfähigkeit. Oder anders: wenige URLs mit ausschließlich geilen Inhalten schlagen viele URLs mit ein paar guten, ein paar mittelmäßigen und ein paar schlechten Inhalten.
Weniger URLs haben darüber hinaus noch viele weitere Vorteile. Um nur ein paar zu nennen:
Weniger Fehlerquellen für Duplicate Content, Indexierungsmanagement, Internationalisierung, u.a.
Stärkerer Fokus von Pagerank und Nutzersignalen auf die wichtigen URLs
Mehr Zeit für die wichtigen URLs Deiner Webseite
Auch der Suchbot hat mehr Zeit und wird weniger abgelenkt (Stichwort Crawlbudget)
Mehr Übersicht bei geringerem Administrationsaufwand
Relaunch mit 10.000 URLs statt 1.000.000 URLs? Der Admin küsst Dir die Füße und Du sparst eine Woche Nerven und Gehalt
Die Webseite abstecken – was gehört dazu, was muss weg?
Bisher fühlt sich der Besuch auf Deiner Webseite an, wie eine Expedition im Paddelkanu in einen unerforschten Seitenarm des Amazonas? Um das in Zukunft zu vermeiden, wollen wir uns im ersten Schritt einen Überblick über den gesamten URL-Umfang der Webseite(n) verschaffen, um dann die groben Schnitzer zu bereinigen. Das Ziel ist es, dass danach nur noch genau eine Version der Webseite online zu erreichen ist. Nennen wir sie:
https://www.meinewebsite.de
Was sind Quellen für Webseiten-Duplikate?
Protokoll-Duplikate: Leitet der Webseitenaufruf von http://meinewebsite.de korrekt (per 301) auf https://meinewebsite.de weiter oder vice versa?
Prefix-Duplikate: Leitet der Webseitenaufruf von www.meinewebsite.de korrekt (per 301) auf meinewebsite.de weiter oder vice versa?
Subdomain und Subfolder: Existieren Subdomains oder Subfolder, über die zusätzliche Versionen der Webseite erreichbar sind?
Domains: Existieren zusätzliche Domains und leiten sie beim Aufruf korrekt (per 301) auf die eigentliche Webseiten-Domain weiter (www.auchmeinewebsite.de auf www.meinewebsite.de)?
Wie findet man Webseiten-Duplikate?
Per Server-Zugriff
Du solltest zunächst Zugriff auf den Server haben, auf dem die Webseite liegt. Damit kannst Du kontrollieren, welche Folder auf dem Server angelegt wurden und wie sie mit dem Folder der Webseite verknüpft sind.
Idealerweise hast Du ebenfalls Zugriff auf das dazugehörige Webseiten-Hosting-Interface. Hier kontrollierst Du, über welche Domains und Subdomains die Webseite erreichbar ist und ob für alle anderen Möglichkeiten außer unserer https://www.meinewebsite.de korrekte 301- Weiterleitungen angelegt sind. Nicht vergessen, pro Domain/Subdomain auch die Einstellungen zum Protokoll (HTTP oder HTTPS) und zum Prefix (www oder nicht) zu überprüfen.
:format(avif))
Abbildung 1: Wie sich Domains verhalten, kontrollierst Du im Webseiten-Hosting-Interface
Per Webseiten-Tracking
Wenn Du in größeren Unternehmen oder für Kunden arbeitest, wird Dir die IT häufig keinen Zugriff auf diese sensiblen Systeme geben können oder wollen. Dann bleibt Dir nichts anderes übrig, als die Webseite von außen zu prüfen.
Dazu lohnt sich es, einen Blick in Dein Webseiten-Tracking zu werfen. Da wir selbstverschuldete Webseiten-Duplikate suchen, die 100% identisch mit unserer Hauptversion sind, ist auch auf allen der gleiche Tracking-Pixel verbaut. Das machen wir uns zunutze.
Besonders einfach ist es, wenn Du Google Analytics verwendest. Richte den folgenden Filter ein, der Dir nicht nur den URL-Pfad, sondern auch den Hostnamen anzeigt. Dann lässt Du Google Analytics einen Monat lang die Webseiten-Zugriffe tracken (der Filter wirkt sich, wie in Google Analytics üblich, nur auf neue Daten aus, nicht auf die bisher gesammelten).
:format(avif))
Abbildung 2: Mit diesem Filter siehst Du den Hostnamen der URL in Google Analytics
Nachdem Google Analytics neue Daten gesammelt hat, kannst Du im Report Behavior -> Site Content -> All Pages sehr schnell erkennen, ob Dein Tracking auf URLs ausgelöst wurde, die nicht Deiner Domain mit korrektem Protokoll und Prefix entsprechen.
:format(avif))
Abbildung 3: Hier könnte sich ein Webseiten-Duplikat verbergen.
Per Externem Crawler
Zusätzlich lohnt es sich, einen externen Crawler über Deine Webseite zu schicken. Dazu bietet sich beispielsweise Ryte an. Stell den Crawler so ein, dass er ebenfalls Subdomains crawlt. Dann prüfst Du die Ergebnisse darauf, ob sich eine Vielzahl von URLs finden lässt, die über ein falsches Prefix oder Protokoll verfügen, die von einer Subdomain oder Subfolder stammen.
Es lohnt sich auch, einen Blick in die externen Links zu werfen. Finden sich hier Domains, die der Hauptversion auffallend ähnlich sind?
Prüfe alles Verdächtige stichprobenartig, um herauszufinden, ob es tatsächlich Duplikate sind.
Pro-Tipp: Es schadet nicht, auch einmal bei früheren / aktuellen Agenturen und Dienstleistern nachzufragen, ob dort noch Webseiten-Duplikate schlummern. Man begegnet tatsächlich hin und wieder Dienstleistern, die es für eine gute Idee halten, 100%ige Duplikate von Webseiten ihrer Kunden online zu stellen. Solche Agenturen halten “SEO” dann auch für einen koreanischen Frauen-Vornamen statt für Online-Marketing…
Grobschnitt – das Unkraut bei der Wurzel packen
Nachdem wir nun die Außengrenzen unserer Webseite gezogen und alles beseitigt haben, was darum herum wuchert, widmen wir uns jetzt ihrem Inneren.
Die erste Aufgabe ist es, alle Bereiche der Webseite zu prüfen und alles zu entfernen, was
Nicht dem Unternehmensziel dient.
Uns daran hindert, bestmöglich in Suchmaschinen zu ranken.
URLs, die dem Unternehmensziel dienen, sind Assets. URLs, die dies nicht tun, sind Ballast und hindern uns daran, dass unsere Webseite übersichtlich, nutzerfreundlich und suchmaschinenoptimiert ist.
„Service-URLs“
Die offensichtlichsten Kandidaten sind die "Service-URLs", wie ich sie nenne (Impressum, Datenschutzerklärung, AGBs, Versandbedingungen, usw.). Diese URLs sind aus rechtlichen Gründen nötig, um eine Webseite (bzw. Onlineshop) zu betreiben, darüber hinaus bringen sie uns aber nur wenig. Da wir sie nicht entfernen können, fügen wir im das Robots-Meta-Tag noindex ein und denken nicht weiter an sie.
Interne Suchergebnisse und Filter-URLs
Interne Suchergebnisseiten sind ebenfalls immer wiederkehrende Kandidaten, die den eigenen Suchmaschinenindex aufblähen. Auch diese können wir leider nicht löschen (da sie dynamisch generiert werden), also fügen wir wieder im das Robots-Meta-Tag noindex ein.
Auch Filter in Onlineshops neigen dazu, unendlich viele unnötige URLs zu produzieren, indem die Filter als URLs mit angehängtem Filter-Parameter eingerichtet sind. Damit das nicht passiert, sind Filter idealerweise mittels AJAX realisiert und sortieren Produkte o.Ä. direkt auf der Seite, ohne sie neu zu laden und die URL zu verändern. Ist das nicht möglich (also kein Budget für die IT frei), dann kann immerhin ein Canonical dafür sorgen, dass die Filterseiten nicht im Index landen (sollten).
Die WordPress-Bild-URLs
Benutzt Du WordPress? Dann klicke einmal auf eines Deiner Bilder und prüfe, ob es sich mit einer neuen URL öffnet. Wenn ja, herzlichen Glückwunsch, Du hast [Anzahl an Bilder] URLs zu viel auf der Webseite. Leider ist das die Standard-Einstellung von WordPress. Wenn Du MySQL beherrschst, kannst Du es direkt für die ganze Website mit einem REPLACE-Statement in der Datenbank korrigieren. Wenn nicht, musst Du es pro Bild händisch korrigieren.
:format(avif))
Abbildung 4: "None" ist die Einstellung, die wir suchen.
Immerhin: WordPress merkt sich die letzte Auswahl in diesem Menü. Wenn Du also einmal "None" ausgewählt hast, ist diese Einstellung auch beim nächsten Bild vorausgewählt.
Tote Bereiche der Webseite
Spannend sind dann besonders noch die Webseiten-„Features", wie man sie (tatsächlich) regelmäßig auf Webseiten mit einer längeren Historie findet. Ein Gästebuch vom Anfang des Jahrtausends, ein (bis auf Spammer) totes Forum oder ein Blog mit wenigen, schlechten Beiträgen von einem kurzfristig begonnenen und dann vergessenen Content-Projekt (mit Kommentar-Spam natürlich). Bei solchen Bereichen einer Webseite fällt die Entscheidung leicht, die Axt anzusetzen. Es sind URLs, die der Webseite wie ein Stein am Bein hängen. Denk nicht lange über eine Optimierung nach. Das kostet nur noch mehr zusätzliche Zeit. Stattdessen: Weg damit!
(Du brauchst Argumentationshilfe gegenüber Deinem Chef? Schau Dir im Webseitentracking die Seitenaufrufe dieser Bereiche an. Das hilft Dir zu belegen, dass es sich wirklich um totes Gewicht handelt.)
Feinschnitt – URLs braucht man nur einmal
Nachdem auch die offensichtlich toten Bereiche der Webseite entfernt sind, geht es nun an die einzelnen URLs. Zuerst prüfen wir sie ebenfalls auf Duplikate.
Produkte sind in einem Onlineshop verschiedenen Kategorien zugewiesen, die jede eine individuelle URL erzeugt? Dein Artikel verfügt über verschiedene Tags und Dein CMS verbaut den Tag jedes Mal in der URL und macht sie damit einzigartig? Es gibt viele Möglichkeiten, warum der gleiche Inhalt auf Deiner Webseite unter mehreren URLs erreichbar sein kann. Nahezu immer ist es unnötig und der Software Deiner Webseite geschuldet.
Wie findet man URL-Duplikate?
Hier kommt wieder der verlässliche Webseiten-Crawler zum Einsatz. Prüfe den Duplicate Content Report in Website Success. Er zeigt Dir verlässlich die möglichen Duplikate Deiner Webseite. Ich prüfe zusätzlich den Word Count der URLs. Ein identischer Word Count ist ein starkes Signal für ein Duplikat.
Häufig lassen sich schnell klare Strukturen erkennen. Die Produkte, die mehreren Kategorien zugeordnet sind, was jeweils eine individuelle URL produziert, sind der Klassiker in 95% aller Onlineshops.
Wie geht man mit URL-Duplikaten um?
Es gibt zwei Wege, mit Duplikaten umzugehen: Entfernen oder einen Canonical setzen. Das Robots-Meta-Tag noindex oder ein Crawlverbot per robots.txt sind dagegen keine Optionen, s. u. warum.
Entfernen
Idealerweise beseitigst Du die Ursache für ein Duplikat. Denn URLs, die nicht mehr existieren, können (langfristig) keine Probleme mehr machen. Nicht immer geht das ohne einen Entwickler, weil der Shop / das CMS für diesen einen Fall nun einmal individuelle URLs vorgesehen hat und Deine IT der Software erst beibringen muss, wie es auch ohne geht.
Diese Lösung ist das mit Abstand nachhaltigste und sicherste Vorgehen, um in Zukunft weitere Duplikate zu vermeiden. Kein Praktikant kann Dein abteilungsübergreifendes, lang einstudiertes Duplikat-Vermeidungs-Protokoll vergessen. Niemand kann im Eifer des Gefechts Deinen Premium-Artikel aus Versehen statt auf einer URL gleich auf einem Dutzend URLs veröffentlichen (Bye bye, hohe Rankings und Traffic-Boost). Und niemand muss dazu gezwungen werden, in regelmäßigen Abständen die Webseite nach Duplikaten durchzuklicken.
Denke an 301-Weiterleitungen, wenn Du Duplikate entfernst, die eine nennenswerte Anzahl an Seitenaufrufen erhalten.
Canonicals
Ist ein Entfernen nicht möglich, greift man meistens auf den Canonical zurück. Mit dem Setzen des Canonicals erklärt man Suchmaschinen, dass diese URL nur eine Kopie ist und sie doch bitte die kanonische Version in ihren Index aufnehmen sollen.
Leider wird der Canonical von Google nur als Hinweis angesehen, nicht als feste Regel, sodass es regelmäßig vorkommt, dass nicht (nur) Deine kanonische Version in den Suchergebnissen erscheint, sondern auch die Duplikate.
Der positive Effekt ist (bzw. sollte sein), dass aller PageRank und alle Nutzersignale der Duplikate der kanonischen Version zugerechnet werden und diese damit stärken.
Noindex
Die Möglichkeit, ein Robots-Meta-Tag noindex zu setzen, ist keine wirklich Alternative.
Vorteil: Suchmaschinen erkennen noindex als feste Regeln an, d.h. eine URL mit einem noindex taucht sehr sicher nicht in den Suchergebnissen auf.
Nachteil: Den Fokussierungseffekt des Canonicals (aller PageRank und Nutzersignale der Duplikate werden der kanonischen Version zugerechnet) gibt es beim Verwenden des noindex nicht. Der PageRank verteilt sich über die interne Verlinkung auf der Webseite, aber leider unfokussiert. Die Nutzersignale verfallen komplett.
Crawlverbot
Die letzte Möglichkeit, ein Crawlverbot per robots.txt zu verhängen, ist ebenfalls nicht die beste Idee.
Der Vorteil: Es spart Crawlbudget.
Die Nachteile: Google mag Crawlverbote nicht, weil Google dann nicht weiß, was sich auf der URL verbirgt. Google kann also seinen Nutzern nicht garantieren, dass der Besuch sicher ist. Im schlimmsten Fall wirkt sich das auf die Bewertung der restlichen Webseite aus. Außerdem ist ein Crawlverbot kein Indexierungsverbot. Das heißt eine URL, die nicht gecrawlt werden darf, kann trotzdem indexiert werden und zwar nur mit den minimalen Informationen, die Google über die interne oder externe Verlinkung über diese URL erhält. Das sieht in den SERPs nie gut aus und rankt entsprechend mies.
Veredeln – Was nicht blüht, muss weg
Häufig performen nicht komplette Bereiche einer Webseite schlecht, sondern es sind einige, wenige URLs, die die Gesamtperformance eines Webseitenbereichs senken. URLs ohne Content, Produkte, die nie gekauft werden oder Artikel, die nicht gelesen werden sind Beispiele dafür. Auch hier lohnt es sich auszusortieren, damit Nutzer und Suchmaschinen ausschließlich hochwertige Inhalte finden und dies mit guten Signalen und besseren Rankings belohnen.
Um herauszufinden, welche URLs besonders gut bzw. besonders schlecht bei Nutzern und Suchmaschinen ankommen, eignet sich ein Blick ins Webseiten-Tracking und in die Google Search Console.
Bitte beachten: Besonders auf großen Webseiten haben nicht alle URLs die gleichen Aufgaben. Es macht daher Sinn, die Performance der URLs mit der anderer URLs mit der gleichen Aufgabe zu vergleichen, statt mit den Durchschnittswerten der gesamten Webseite. Google Analytics bietet dazu die Möglichkeit, URLs mittels Content Groupings in Bereiche zu clustern.
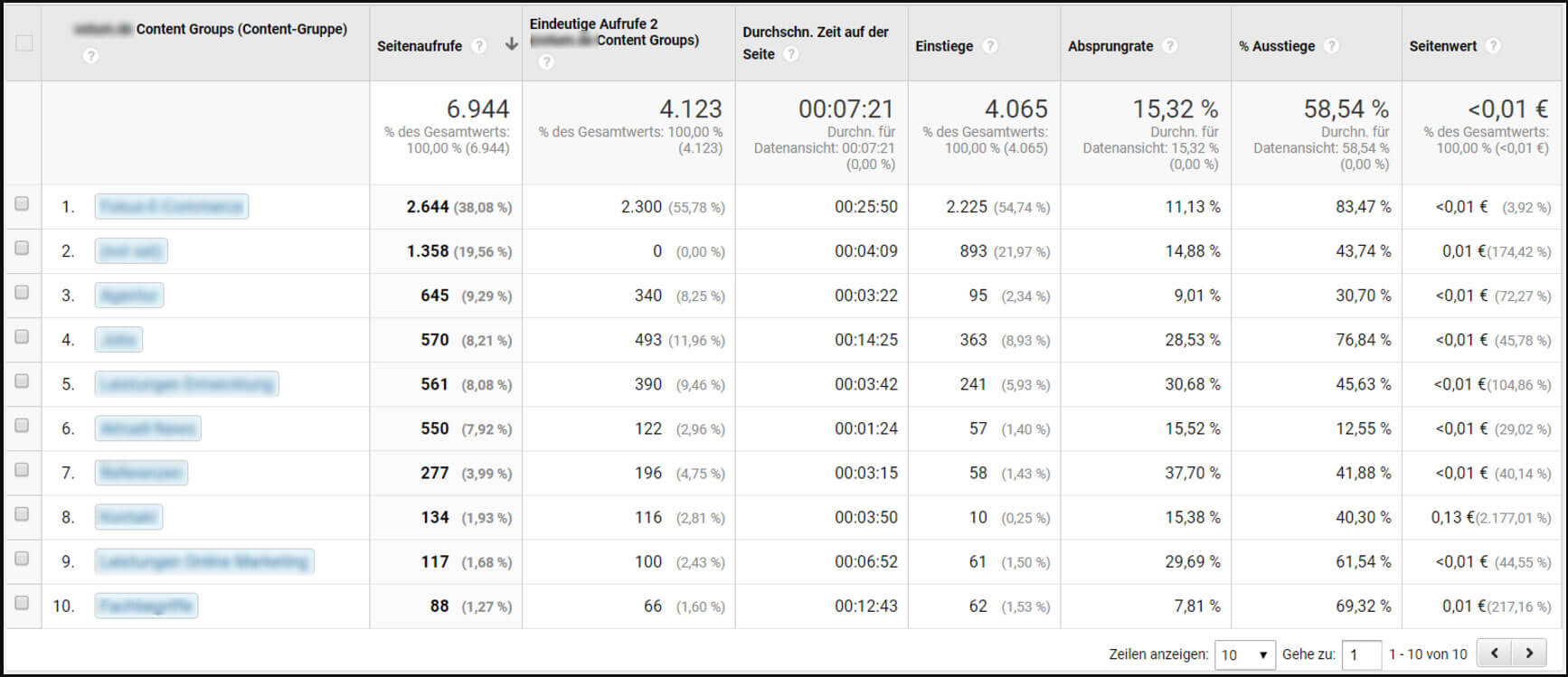
Abbildung 5: Auswertung von Content Groupings in Google Analytics
Folgende Kennzahlen eignen sich zur Bewertung der Performance von URLs:
Google Analytics
Anzahl und Höhe der Conversions (Produkt-URLs)
Anzahl und Höhe der erreichten Goals
Seitenbesuche
Verweildauer
Bounce Rate
Einstiege und Ausstiege
Google Search Console
Anzahl und Relevanz der Rankings
Rankingposition
Impressions
In je mehr Kennzahlen eine URL schlecht abschneidet, umso deutlicher stehen die Zeichen auf Löschung der URL. Zwar hilft auch, erst einmal ein noindex zu setzen, in der festen Überzeugung, die URL später zu optimieren. Aus unserer Erfahrung ist "Das optimiere ich später" allerdings die häufigste Ausrede, um für lange Zeit unnötigen Suchmaschinentraffic zu vergeben. Besser ist es, gleich den richtigen Schritt zu tun.
Dazu ist es natürlich nötig, (selbst-)kritisch zu sein, auch wenn es manchmal weh tut. Webseiten quellen seit "Content ist King" über vor schlecht gemachten Inhalten. Sei ehrlich zu Dir selbst und Deinem Unternehmen. Würdest Du das selbst wirklich lesen wollen? Willst Du wirklich, dass Dein Unternehmen noch länger mit schlechtem Content in Verbindung gebracht wird? Na also!
Wenn Dein Chef in drei Monaten auf die Besucher- und Umsatzzahlen schaut, wird er es Dir danken, dass Du die Courage hattest, ihm ins Gesicht zu sagen: "Das schadet uns, das muss weg!"
Fazit – Dein Webseiten-Schrebergarten
Wir haben uns jetzt vom großen Außen ins kleine Innere der Webseite vorgearbeitet und Quellen für unnötige URLs beseitigt. Das kann in der Praxis zu dramatischen Änderungen der Anzahl der vorhandenen URLs führen.
Beispiel: Wir haben nach der vollständigen Analyse der Webseite eines Kunden (Dienstleister mit einem kleinen Onlineshop mit 50 Produkten) über 180.000 URLs gefunden. Google hatte davon gerade einmal 3.000 URLs indexiert. Nach Abschluss unserer Optimierung waren davon nur noch 2.420 URLs übrig, von denen Google bisher 1.490 indexiert hat. Die Webseite hat seitdem deutlich an Rankings und Traffic zugelegt.
Derzeit arbeiten wir für einen Kunden, für dessen Onlineshop wir über 3.000.000 URLs gefunden haben (weniger als 5.000 sind indexiert). Nach der Optimierung werden davon etwa 100.000 URLs übrig bleiben. Wir freuen uns schon darauf, wenn sich die Optimierungen in Google bemerkbar machen.
Analysiere Deine URL-Struktur mit Ryte FREE
Veröffentlicht am Jul 4, 2017 von Eico Schweins