Rich Snippets
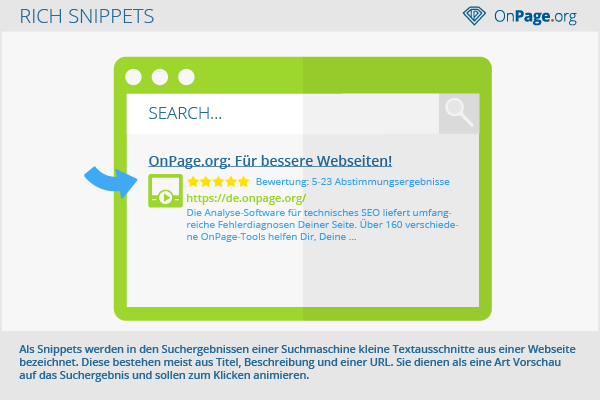
Rich Snippets stellen eine erweiterte Form von Snippets dar, die spezielle Elemente wie Bewertungssterne, Verlinkungen, Abbildungen, Preisangaben und weitere Informationen enthalten können. Als Snippets werden in den Suchergebnissen einer Suchmaschine kleine Textausschnitte aus einer Webseite bezeichnet.
Diese bestehen meist aus Titel, Beschreibung und einer URL. Sie dienen als eine Art Vorschau auf das Suchergebnis und sollen im Idealfall einen Call-to-Action enthalten. Häufig verwenden Suchmaschinen wie Google die Meta Description sowie den Meta Title der Zielseite für das Snippet. Allerdings kann Google das Snippet auch aus Textversatzstücken der Seite selbst “zusammenbauen”.
Allgemeine Informationen zum Thema
Rich Snippets stellen eine erweiterte Form von Snippets dar, die spezielle Elemente wie Bewertungssterne, Verlinkungen, Abbildungen, Preisangaben und weitere Informationen enthalten können. Diese Zusatzinformationen können durch bestimmte Formatierungen im Quellcode markiert werden. So können Suchmaschinen die Ergebnisse in den SERPs besonders hervorheben. Somit können die Besucher schneller ermitteln, ob das Suchergebnis für ihre Suche relevant ist. Mit Hilfe von Rich Snippets können die Click-Through-Rate eines Snippets sowie Klickraten allgemein erhöht werden.

Vorgehensweise
Um Rich Snippets in den Suchergebnissen darstellen zu können, müssen die Informationen im Quellcode vorhanden sein und entsprechend markiert werden. Die Vorgehensweise kann in zwei Schritten erfolgen:
Es gibt drei Möglichkeiten, Rich Snippets im Quellcode zu implementieren. Um diese auf einer Webseite zu hinterlegen, sind HTML-Kenntnisse erforderlich. Als Auszeichnungssprachen werden grundsätzlich Mikroformate, Mikrodaten und RDFa von Google akzeptiert. Es gibt verschiedene Informationsarten, die Google unterstützt. Für folgende Informationen kann Google Rich Snippets einblenden:
- Bewertungen, zum Beispiel über Aggregaterating
- Personen, Autoren
- Unternehmen und Organisationen
- Rezepte
- Produkte
- Veranstaltungen
- Musik
- Preise
- Videos
- Urheberinformationen
Schema.org bietet eine Sammlung von HTML-Tags und Markups, die für die Verwendung von Rich Snippets angewendet werden können. Webmaster können sich ganz einfach auf Schema.org die entsprechenden Markups heraussuchen. Suchmaschinen lesen die strukturierten Daten daraufhin heraus und spielen die entsprechenden Rich Snippets in den Suchergebnissen ein. Suchmaschinen legen einen großen Wert auf strukturierte Daten, da diese dadurch zugänglicher werden. In der Google Search Console wird der Data Highlighter zur Verfügung gestellt. Durch dieses Tool können einige relevante Daten auf einer Website markiert werden, auch ohne den Quellcode mit Markup-Language zu ergänzen.
Möglichkeiten zur Realisierung von Rich Snippets
Je nach Einsatzzweck und verwendetem Standard lassen sich verschiedene Möglichkeiten unterscheiden, mit denen Rich Snippets umgesetzt werden können:
Mikrodaten: Mikrodaten ermöglichen es, mithilfe von HTML5 Informationstypen zu deklarieren und diese mit Eigenschaften zu belegen. Dadurch können beispielsweise Bewertungen, Personen, Produkte, Unternehmen, Rezepte, Veranstaltungen, Organisationen und Videos mithilfe eines speziellen Vokabulars realisiert werden[1]. Eine mit Mikrodaten im Quellcode markierte Person könnte folgendermaßen aussehen:

Durch die Angabe von itemscope innerhalb des Tags wird deklariert, dass nun ein Element folgt. Dieses wird durch itemtype="http://data-vocabulary.org/Person" als das Element „Person“ spezifiziert. Das Element wird nun über die Einführung itemprop=" " um Eigenschaften ergänzt. Innerhalb der Anführungsstriche steht die Bezeichnung der Eigenschaft, beispielsweise name (Name), title (Beruf), affiliation (Unternehmen/Organisation), url (Website) oder address (Adresse). Einen Sonderfall stellt die Eigenschaft „address“ dar, die durch Untereigenschaften wie locality und region weiter untergliedert werden kann.
Mikroformate: Auch Mikroformate realisieren Rich Snippets über HTML-Tags. Innerhalb eines Tags definiert man über ein class-Attribut sogenannte Entitäten sowie deren Eigenschaften. Um die Vorstellung einer Person zu realisieren, wird das Mikroformat hCard verwendet, das im Quellcode über class="vcard" registriert wird. Das oben genannte Beispiel sieht in Mikroformaten so aus:

Auch hier wird die Person anhand verschiedener Eigenschaften weiter definiert und erneut wird die Adresse durch weitere Untereigenschaften gesondert spezifiziert. Die Definition der einzelnen Eigenschaften erfolgt über den String class=" ". Es ist kein Zufall, dass die meisten Eigenschaften denselben Namen tragen wie bereits weiter oben im Beispiel zu den Mikrodaten. Die für Mikrodaten verwendeten Eigenschaften basieren auf dem Mikroformat hCard[2].
RDFa: Auch RDFa ermöglicht es, Elemente mit entsprechenden Eigenschaften einzuführen und darüber Bewertungen, Personen, Rezepte und weitere Elemente für Rich Snippets verfügbar zu machen. Im Unterschied zu Mikrodaten und -formaten verwendet RDFa allerdings XHTML-Tags, um diese zu definieren.[3] Das oben genannte Beispiel würde in RDFa umgesetzt folgendermaßen aussehen:

Die Namespace-Deklaration mithilfe von xmlns zeigt an, welches Vokabular für die Definition der Elemente und ihrer Eigenschaften verwendet wird. Mit typeof="v:Person" wird definiert, um welche Art von Element es sich handelt, in diesem Fall um eine Person. Soll eine Eigenschaft eingeführt werden, erreicht man dies mithilfe des Strings property="v:Eigenschaft". Anstelle von „Eigenschaft“ muss die korrekte Bezeichnung laut Spezifikation eingesetzt werden. Bei der Angabe von URLs wird stattdessen das rel-Tag verwendet. Wie schon bei Mikrodaten und -formaten werden auch bei RDFa die Adressdaten geschachtelt mithilfe von Untereigenschaften angegeben.
Unterschiede zwischen Mikrodaten, Mikroformaten und RDFa
Mikrodaten sind seit einiger Zeit der einzige Standard, der von Schema.org unterstützt wird[4]. Dementsprechend sind Mikrodaten von allen großen Suchmaschinen anerkannt und werden anstandslos umgesetzt. Einer der Vorteile von RDFa ist hingegen die einfache Erweiterbarkeit im Gegensatz zu den zwei anderen, hinsichtlich der Erweiterungsmöglichkeiten eher beschränkten Standards. Mikroformate hingegen sind besonders einfach anzuwenden und lassen sich daher schnell umsetzen.
Änderungen im August 2021
Problematisch wird es, wenn Rich Snippets zwar vorbereitet werden, aber nicht den gewünschten Effekt – also Rich Results – bringen. Dies geschieht, wenn es Fehler im Code gibt. Google ist diesem Problem begegnet, indem seit 2021 Status-Berichte zur Verfügung stehen, die in der Google Search Console hierzu Informationen bereitstellen.
Mit dieser Änderung geht einher, dass von Google seit dem 1. August 2021 in der Search Console keine generischen Informationen mehr zu den Rich Results angezeigt werden.
Beispiele für die Verwendung von Rich Snippets
Hier einige Beispiele aus einer Vielzahl von Anwendungsmöglichkeiten von Rich Snippets (eine nicht vollständige Aufstellung befindet sich weiter oben im Artikel):
Arbeitgeber-Gesamtbewertung: Für Arbeitgeber, die sich präsentieren möchten, ist die Zusammensetzung aller Bewertungen von Vorteil, weil sie eine hohe Aussagekraft hat. Artikel: Gemeint sind vor allem Blogartikel. Insbesondere, wenn ein mobiles Gerät benutzt wird und Websites lange und hochwertige Texte haben, sind Rich Snippets hier vorteilhaft. Bücher: Anbieter von Büchern und E-Books profitieren von Listen, in denen sie aufgenommen werden und so leichter ihre Zielgruppe erreichen können. Für die User wird über das Snippet das gewünschte Buch in den SERPs sichtbar. Datensätze: Das Finden von Datensätzen – etwa aus den Bereichen Regierung und Bürger oder Wissenschaft – wird durch den Einsatz von Rich Snippets erleichtert. Faktenchecks: Nachdem eine Website einen Sachverhalt dargestellt hat, erfolgt eine entsprechende Bewertung. Google fast daraufhin den Faktencheck in Rich Snippets zusammen. Frage-Antwort-Seiten: Die Kategorie „Question & Answer“ ist im Laufe der Zeit immer beliebter geworden. Dabei wird eine Liste mit Antworten auf Fragen erstellt. Die Antworten sind teils richtig und teils falsch. Snippets helfen dabei, die richtigen von den falschen Antworten zu unterscheiden.
Weitere Kategorien sind etwa Karussell, lokale Unternehmen, beliebte Orte, Logos, Kurse, persönliche Profile und weitere mehr.
Schattenwebsites und Rich Snippets
Rich Snippets können auch zu Wettbewerbszwecken eingesetzt werden, wie der Fall des Lieferservices Lieferando zeigt.
Lieferando hatte bereits im Jahr 2011 angefangen, Websites von Restaurants, mit denen Kooperationen bestanden, fast identisch zu kopieren, lediglich die Endungen unterschieden sich. Jedes Restaurant erhielt eine Domain, zuweilen Foodtypes, Farbentemplates und Unique Content. Zudem wurden Rich Snippets automatisch erstellt.
Dadurch wurden die Seiten, die Lieferando erstellt hatte, in den Suchergebnissen vor den originalen Seiten der Restaurants angezeigt. Die Conversionrate lag zuweilen bei 76 Prozent, die Betreiber der Restaurants gerieten ins Hintertreffen.
Sinn des Projektes mit dem Namen „Satellit“ war es, die Seitenbesucher zum Bestellen über Lieferando zu bewegen. Bei Bestellungen, die über die Seite der Restaurantbetreiber aufgegeben wurden, erhielt Lieferando keine Provision, wurden die kopierten Seiten benutzt, war das Unternehmen dagegen am Umsatz beteiligt.
Illegal ist diese Praxis nicht. Doch sie wird allgemein als unfair betrachtet, auch weil der direkte Zugang zum Kunden über den „Umweg“ Lieferando erschwert bzw. unmöglich gemacht wird.
JSON-LD als Alternative
Strukturierte Daten können mit Hilfe von JSON-LD ebenfalls an Google und andere Suchmaschinen übergeben werden. Der Vorteil dieser Methode besteht darin, dass die Markierung der Seitenelemente über ein Skript ausgelagert wird. Somit muss nicht der Quellcode selbst verändert werden.
JSON-LD arbeitet mit Namen-Wert-Paaren und sorgt so für eine eindeutige Zuordnung der strukturierten Daten. Die Zuordnung erfolgt auf den gleichen Schemata wie bei anderen Auszeichnungssprachen. So kann zum Beispiel eine Veröffentlichung mit JSON-LD ausgezeichnet werden:

Testen
Nachdem die entsprechenden Mikrodaten im Sourcecode hinterlegt sind, kann es mittels eines speziellen Rich Snippets Tools für strukturierete Daten getestet werden. Werden Rich Snippets im Testing Tool angezeigt, kann davon ausgegangen werden, dass diese demnächst in den Suchergebnissen erscheinen. Erfahrungsgemäß kann dies jedoch einige Wochen dauern.
Bedeutung für die SEO
Die Gestaltung des Snippets spielt eine große Rolle für die Entwicklung der Klickraten eines Suchergebnisses. Diese Click-Through-Rate eines Suchergebnisses fließt als wichtiger Faktor für die Bewertung und für das Ranking einer Webseite mit ein. Mittels Rich Snippets können einzelne Suchergebnisse hervorgehoben werden, da viele auffällige Elemente wie Videos, Bilder, Sterne usw. eingesetzt werden. Unter den normalen Suchergebnissen fällt der Einsatz von Rich Snippets besonders auf und kann dazu führen, dass das Snippet häufiger angeklickt wird. In der Suchmaschinenoptimierung hat sich inzwischen mit der Rich-Snippet-Optimierung eine eigene Nische herausgebildet.
Einzelnachweise
- ↑ Über Mikrodaten. Google Support. Abgerufen am 19. Januar 2014.
- ↑ Über Mikroformate. Google Support. Abgerufen am 19. Januar 2014.
- ↑ Über RDFa. Google Support. Abgerufen am 19. Januar 2014.
- ↑ schema.org FAQ. Google Support. Abgerufen am 19. Januar 2014.
- ↑ fehler details rich result report t3n.de. Abgerufen am 15.11.2021.</ref
- ↑ rich snippets leitfaden onlinesolutionsgroup.de. Abgerufen am 15.11.2021.</ref
- ↑ [1] tageskarte.io. Abgerufen am 16.11.2021.</ref